概述
本文将深入RocketMQ,详细描述RocketMQ是如何存储消息的。包括存储的文件格式、0拷贝技术、文件的顺序写、hash槽、索引文件、消费文件、刷盘方式等等。
文章回答以下问题
-
RocketMQ的存储的架构设计和存储模型是什么样的?
存储架构图、存储文件在磁盘上的组织方式、一条消息的存储过程、消息的存储模型
-
RocketMQ中如何保证消息的高效读写的?
0拷贝、顺序写、NIO中的直接内存映射、IndexFile索引、异步刷盘
-
RocketMQ中消息存储的刷盘方式?
同步、异步
存储的架构设计和存储模型
通过存储的架构描述消息的整体存储的过程全貌,这张图可以知道存储中使用了哪些技术以及他们是如何配合使用的。然后针对存储文件在磁盘上的组织方式做一个详细说明,通过这个过程就知道消息的数据文件有哪些,在磁盘上是怎么组织的。最后通过描述一条消息的存储过程每个核心组件以及组件内容格式做一个详细说明,每个文件的详细内容是什么。
存储架构
消息通过生产者发送给broker,broker会存储到CommitLog、IndexFile、ConsumeQueue,然后通过mmap写入内存,最后刷盘到磁盘(注意:异步刷盘就是定期触发的)。
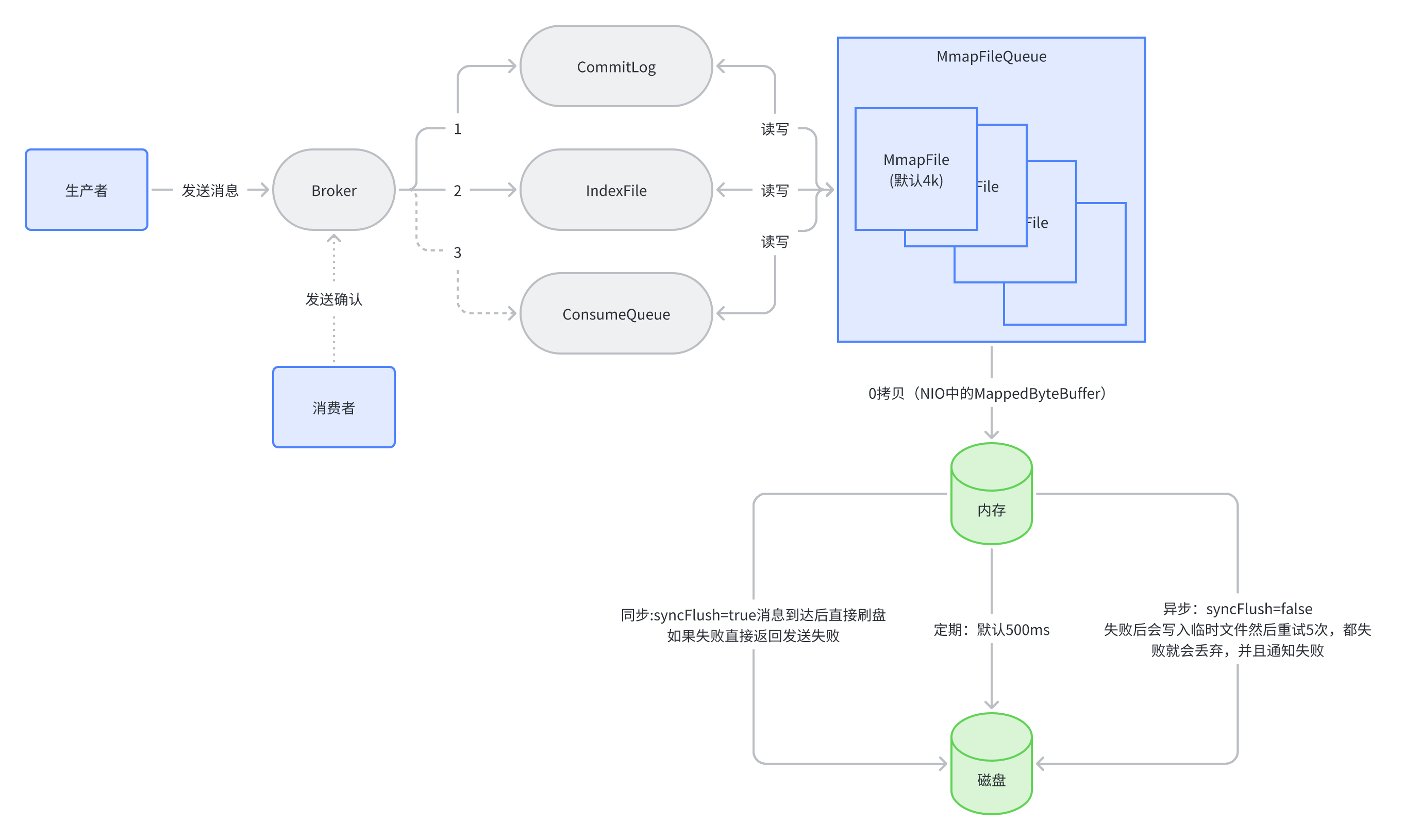
在磁盘上存储文件的组织方式
CommitLog是消息的存储文件,顺序写,随机读。IndexFile是消息的索引文件,方便快速查询消息。ConsumeQueue是消息的消费信息文件。
-
CommitLog:CommitLog用于存储消息的文件。它是由多个固定大小的文件组成,每个文件的大小默认为1G(原因是Java中MappedByteBuffer最大是1.5G)。如果当前文件已经写满,则会新建一个文件来存储新的消息。
-
IndexFile:每个IndexFile的大小在源代码中是这么计算的:
this.fileTotalSize = IndexHeader.INDEX_HEADER_SIZE + (hashSlotNum * hashSlotSize) + (indexNum * indexSize);
// IndexHeader.INDEX_HEADER_SIZE = 40
// hashSlotNum = 5000000(500万)
// hashSlotSize = 4
// indexNum = 5000000 * 4
// indexSize = 20
// 所以默认大小是:(40 + (5000000*4) + (5000000 * 4 * 20))/1024/1024 = 381.4697265625M
-
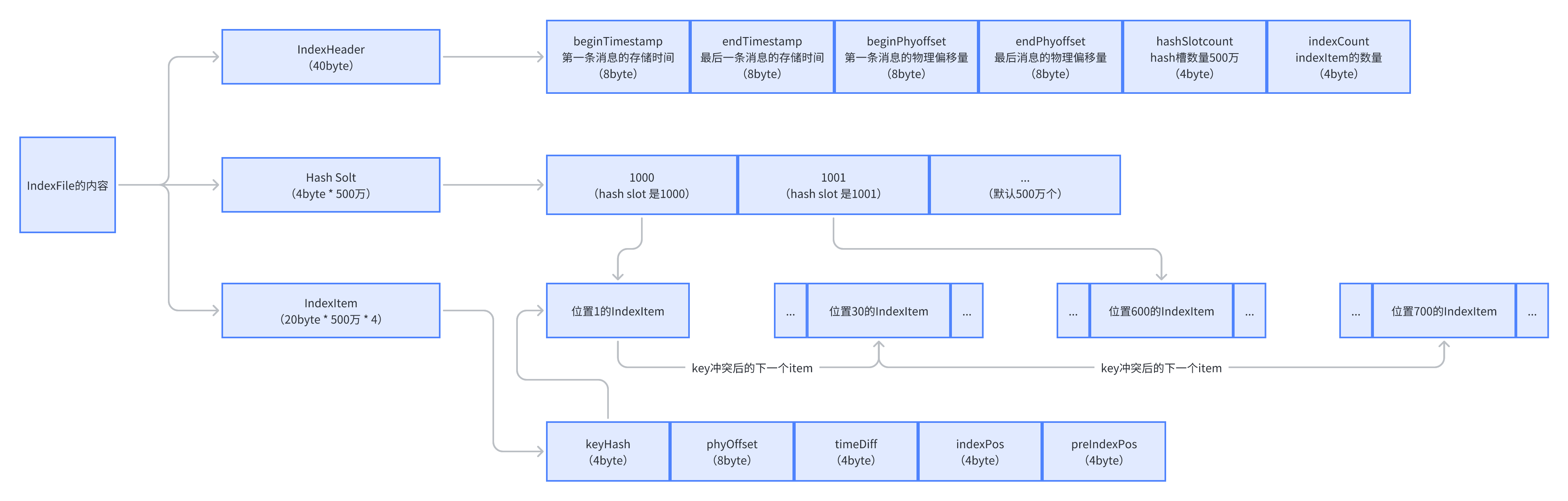
Index Header: 固定为40字节,包括4字节的magic code("Index"),4字节的版本号,4字节的索引项个数,4字节的第一个索引项的偏移量,4字节的最后一个索引项的偏移量,4字节的最后一个索引项的时间戳,16字节的保留字段。
-
Hash slot: 固定为4字节,表示hash桶的索引值。
-
Index Item: 固定为20字节,包括8字节的消息物理偏移量,4字节的消息长度,4字节的key长度,4字节的tag长度。
-
ConsumQueue:每个topic对应的MessageQueue对应一个文件。默认30W条消息。
一条消息到存储过程
会按照这个顺序写入:CommitLog->IndexFile->(如果有消费)ConsumeQueue->(更新)CommitLog
1、当broker收到消息会先存储到CommitLog。
- 同步:同步消息会触发刷盘保证写入到MmapFile的同时写入到磁盘,写入磁盘失败就返回失败。如果有从节点,同时也需要写入从节点成功。
- 异步:异步消息写入到内存MmapFile中后直接返回成功。只需要主节点写入成功就返回成功。如果5次写入失败就通知失败(生产者和broker会保持一个长连接接收通知)。
- OneWay:和异步的逻辑一样,只是不需要保持长连接等待结果。
2、存入CommitLog后会继续写入IndexFile,如果CommitLog写入成功但是IndeFile写入失败,重启的时候会重建,但是没有重启的时候会导致找不到消息,因为都是通过Mmap写入的所以写入失败的机率可以忽略不计。同步、异步、OneWay刷盘的逻辑和CommitLog一样。
注意:如果在写入CommitLog成功但写入IndexFile时失败,RocketMQ会尝试将失败的IndexFile写入操作存储在内存中,然后将消息发送到消费者。在后续操作中,RocketMQ会不断尝试将失败的IndexFile写入到磁盘中,直到写入成功。在这个过程中,如果Broker崩溃了,已经写入CommitLog但没有写入IndexFile的消息将无法被消费者消费。RocketMQ在处理写入失败的情况下,会尝试最大限度地保证数据的安全性,但不能保证100%。
3、如果消费者消费了消息,会写入到ConsumeQueue,并且会去CommitLog更新消费状态。
消息的存储模型
CommitLog
CommitLog的每个条目是按照如下格式存储的:
| 序号 |
字段名称 |
字段长度 |
说明 |
| 1 |
TotalSize |
4字节 |
消息条目总长度 |
| 2 |
MagicCode |
4字节 |
固定值为0xAABBCCDD的消息标识码 |
| 3 |
BodyCRC |
4字节 |
消息体的CRC校验码 |
| 4 |
QueueId |
4字节 |
消息所属的队列ID |
| 5 |
Flag |
4字节 |
消息的Flag |
| 6 |
QueueOffset |
8字节 |
消息在队列中的偏移量 |
| 7 |
PhysicalOffset |
8字节 |
消息在CommitLog文件中的物理偏移量 |
| 8 |
SysFlag |
4字节 |
系统标识位 |
| 9 |
BornTimestamp |
8字节 |
消息的生产时间戳 |
| 10 |
BornHost |
可变 |
消息的生产者IP地址 |
| 11 |
StoreTimestamp |
8字节 |
消息的存储时间戳 |
| 12 |
StoreHostAddress |
可变 |
消息存储服务器的IP地址 |
| 13 |
ReconsumeTimes |
4字节 |
消息被重新消费的次数 |
| 14 |
PreparedTransactionOffset |
8字节 |
事务消息的准备事务偏移量 |
| 15 |
Body |
可变 |
消息体 |
| 16 |
Topic |
可变 |
消息主题 |
| 17 |
Properties |
可变 |
消息属性 |
IndexFile
IndexFile由IndexHeader、Hash Slot、IndexItem组成。
例如查询主题是T中的M消息的物理偏移量:
- 计算hash slot:hashCode(T#M)% 500万,计算的槽是1000
- 槽1000中存的IndexItem位置是1。(哪个槽应该对应哪个IndexItem?下一个IndexItem位置=IndexHeader+HashSlot+IndexCount)
- 把槽1000中所有的IndexItem查询出来就是物理偏移量了
- (最后把物理偏移量拿到CommitLog中查询出来对比消息ID或者KEY就能找到唯一的消息)
保证消息的高效读写
RocketMQ中会通过一个MmapFileQueue队列来维护所有存储文件的MmapFile,也就是CommitLog、IndexFile、ConsumeQueue文件在程序中都是通过MmapFile读写的。MmapFile默认是4K,是通过Java的NIO中的MapedByteBuffer直接把文件映射到内存中,通过MmapFile直接读写文件,并且写入的时候是顺序写入的,所以效率会很高。另外RocketMQ中的IndexFile可以提高消息的查询速度,异步刷盘也能提高消息的吞吐量。
0拷贝
RocketMQ中的0拷贝技术是通过MappedByteBuffer实现的,实际上只是减少了一次从用户空间到内核空间的拷贝。也就是读写的4次拷贝变成了3次拷贝。
具体来说,当生产者发送消息时,首先将消息写入MappedFile,同时生成一条消息索引信息,并将索引信息写入IndexFile。在写入MappedFile的过程中,RocketMQ使用ByteBuffer类来映射MappedFile中的一块内存区域,通过这个ByteBuffer对象来直接操作内存,避免了消息数据的拷贝。当消费者拉取消息时,RocketMQ也使用ByteBuffer来映射MappedFile中的消息数据,避免了数据在内存中的复制。这样做可以有效减少系统开销,提高消息存储和读取的效率,同时也有利于降低系统的延迟。
顺序写和IndexFile
RocketMQ中,消息的存储是采用顺序写的方式,也就是按照消息到达的顺序,将消息写入CommitLog,确保消息按照产生的顺序被存储。具体来说,RocketMQ的顺序写包括以下几个步骤:
- 消息被发送到Broker,Broker收到消息后将其放入内存缓存队列中。
- 当内存缓存队列的消息数量达到一定阈值或者一定时间间隔到达时,会将内存缓存队列中的消息刷写到磁盘中的CommitLog文件中,这个过程是顺序写的过程。
- 在将消息写入CommitLog之前,RocketMQ会对消息进行序列化和压缩处理,并在消息的前面添加一些元数据,如消息长度、消息类型、消息主题等信息,这样可以方便后续的消息读取和解析。
- 在消息写入CommitLog之后,会将消息的索引信息写入到IndexFile中,IndexFile中维护了消息索引信息和CommitLog的文件偏移量的映射关系,方便后续的消息查询和检索。
顺序写的好处在于可以避免随机写的开销,降低磁盘的寻道次数,提高磁盘的写入效率,从而实现高吞吐量和低延迟的存储。此外,RocketMQ还通过一些优化措施,如使用内存缓存队列、对消息进行批量处理等方式进一步提升存储性能和效率。
异步刷盘
RocketMQ中的异步刷盘是指在消息写入CommitLog之后,不立即将消息内容同步到磁盘中,而是将消息内容缓存在内存中,定期批量异步刷盘到磁盘中,以提高消息写入的性能和效率。默认情况下会每500ms定时刷盘。同时,为了保证数据不丢失,RocketMQ还会对刷盘进行一些安全机制的保证,在同步刷盘失败时进行重试,默认重试5次。
异步刷盘相较于同步刷盘,可以显著提高消息的写入性能和吞吐量,但也存在一定的风险,因为如果在消息写入后未及时刷盘就出现了机器宕机等异常情况,可能会造成数据的丢失。因此,在实际应用中,需要根据实际需求和数据安全等级选择是否使用异步刷盘。
消息存储的刷盘方式
RocketMQ中有2种刷盘方式:同步、异步。发送同步消息的时候会同步刷盘,异步消息的时候会异步刷盘,当数据大小超过阈值或者定期会触发刷盘。
同步
当用同步方式发送消息的时候,消息写入到MmapFile的时候会马上触发刷盘,如果有主从复制则还需要从节点也刷盘成功,最后才返回消息发送成功,因为过程很多所以同步消息的效率会非常低。
异步
RocketMQ的异步消息有2中触发方式:定期触发、内存缓存达到一定的大小阈值。默认每500ms会触发一次刷盘或者内存缓存达到阈值也会触发刷盘。
异步发送消息的时候,Broker会在消息成功写入CommitLog后,通过长连接通知Producer消息发送成功。具体来说,当Broker收到异步发送消息的请求后,会立即返回发送成功的响应,同时将消息保存到内存的写缓存中。随后,Broker会启动一个单独的线程,将写缓存中的消息刷写到磁盘的commitlog文件中,并更新IndexFile。当消息成功写入CommitLog后,Broker会将写入的消息的物理偏移量和消息的存储时间等信息构成响应对象,通过长连接返回给Producer。Producer可以通过设置回调函数来处理这个响应对象,以便在消息成功写入Broker后进行进一步处理。当然,如果异步刷盘失败,Broker也会通过回调函数将失败的信息通知给Producer,以便Producer进行处理。